# 索引
# 索引类型
# InnoDB索引
聚簇索引(聚集索引)
- 主键索引
辅助索引(二级索引)
- 单值索引
- 复合索引(联合索引 -> 覆盖索引)
- 唯一索引(可升级为聚簇索引)
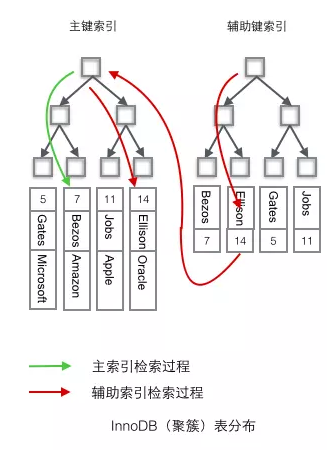
聚簇索引具有唯一性
聚簇索引树按照主键顺序依次存放数据,故使用自增主键,插入数据时无需移动旧数据,效率高
InnoDB聚簇索引的优势:
- 主键和行数据存储在同一棵B+树,一同被载入内存,当获取行数据时IO次数更少
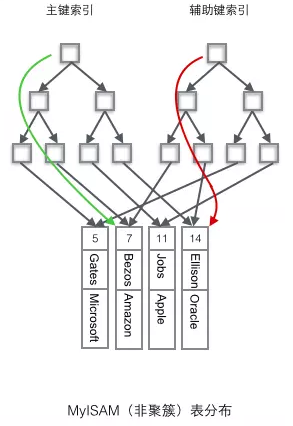
- 辅助索引的叶子节点存储主键值,而非数据的物理地址(MyISAM非聚簇索引方案),当行数据发生可能的移动或页分裂时无需对辅助索引树进行额外维护
辅助索引 -> 辅助索引 -> 主键值 -> 聚簇索引树 -> 行数据的查询过程称作“回表”
# 索引结构
- BTree/B+Tree/B*Tree
- Hash(InnoDB、MyISAM均不支持)
- Full-Text(MyISAM支持)
- RTree(MyISAM支持)
使用B+树的优势
- 数据统一存储在叶子节点中,每个节点存储的key数量更多;查询深度稳定
- 叶子节点维护有序链表,区间查询性能较好
不适用索引的场合
- 表数据量较少
- 表字段频繁更新
- 表字段使用频次较少
# 索引高度
索引树高度应维持在3~4之间
# 索引设计策略
- 数据行数过多
- 分库分表
- 字段长度过长或类型空间占用过长
- 字符串列尽量采用前缀索引
- 减小索引字段大小,增加页中存储索引量,有效提高索引查询速度
order by语句无法使用前缀索引
- 尽量使用
VARCHAR - 尽量使用
ENUM作为常量值
- 字符串列尽量采用前缀索引
# SQL优化
# set global slow_query_log='ON'; // 开启慢 SQL 日志
# set global slow_query_log_file='/var/lib/mysql/test-slow.log'; // 记录日志地址
# set global long_query_time=1; // 最大执行时间
show variables like 'slow_query%';
show variables like 'long_query_time';
# 执行计划
id
select_type
table
type
ALL全表扫描INDEX全索引扫描- 需要遍历整棵索引树
RANGE索引范围扫描OR/IN查询无法直接沿叶子节点指针遍历获取结果集,执行效率低,需优化为UNION- 聚簇索引的不等值查询类型为
RANGE,辅助索引的不等值查询类型为ALL
REF非唯一索引等值查询,及唯一索引最左原则匹配扫描(❓)EQ_REF- 常见于多表连接中使用主键和唯一索引作为关联条件的场景,此时被驱动(连接)的表(子表,左表❓)连接字段应为主键或唯一索引,执行计划类型为EQ_REF
CONST主键/唯一键的等值查询(在索引树第一层即发生索引命中)
possible_keys
key
key_len索引覆盖长度
单值索引
- 对于可能为NULL的字符字段,覆盖长度为1(用于标识是否为空的预留字节)+2(用于标识
VARCHAR类型的开始与结束位置)+字符长度✖️单字符最大预留字节长度(编码为utf8mb4时最大预留字节长度为4,编码为utf8时最大预留字节长度为3) - 索引覆盖长度应尽可能短(以节省索引树叶子节点空间占用)
- 对于可能为NULL的字符字段,覆盖长度为1(用于标识是否为空的预留字节)+2(用于标识
复合索引
- 索引覆盖长度应尽可能长(以尽可能多地使用复合索引)
ref
rows
Extra
# 执行性能
# SHOW PROFILES
SHOW PROFILE [type [, type] ... ]
[FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
# SHOW PROCESSLIST
# 索引优化策略
# 单表
覆盖索引与最左前缀规则
(执行等值查询时)查询条件字段应从(复合)索引的最左前列进行,且被索引完全覆盖,可避免回表。即,查询条件字段不跳过可用索引中的任何列(且不能在索引中的任何列上使用范围查询、按照范围查询的字段不能被索引覆盖),或是索引字段的子集。若发生索引中断,索引覆盖长度只取决于中断前的索引字段
当查询条件字段被索引完全覆盖时,即使字段排列顺序与索引顺序不一致也能使用索引(查询优化器将按照索引顺序对字段排列顺序进行调整):因此在实际使用时,唯一值较多的字段排列顺序应尽量在前(有可能过滤更大比例的数据)
(索引字段用于排序或分组时)排序字段的顺序须与索引字段严格一致,也应从索引的最左前列进行(除非某个排序字段为常量),且方向一致,此时直接依赖索引进行结果集排序,不产生
using filesort(而是using index),但排序/分组时所依赖索引的覆盖长度不在执行计划key_len中体现
索引失效避免
- 查询结果集数据量尽量小(占原表的25%以下,否则可能不会使用索引)
- 不在索引列上做任何二次加工操作
- 模糊查询时%写在查询关键词右侧
VARCHAR类型字段须加上单引号,否则无法使用索引,也可能导致行锁降级为表锁
不直接对大表进行
COUNT(*)/COUNT(1)行数统计操作,而使用执行计划中ROWS近似值代替,或额外维护一份汇总表;若此时表中存在辅助索引,优化器将借助辅助索引统计行数,一定程度上减少I/O操作
# 多表
- 小表驱动(连接)大表:驱动表查询时无法沿索引查找(
ALL),故数据量应尽可能少;小表上关联列上不建立索引 - 子表上的被连接字段需要添加索引,或直接使用主键索引作为被连接字段
# 排序/分组
单路复用排序中是否出现
sort_buffer_size/max_length_for_sort_data瓶颈❓
# InnoDB执行引擎
# 逻辑架构
- 连接层
- 服务层
- 引擎层
- 存储层
# 并发事务
# 隔离级别
读未提交(RU)
存在脏读、不可重复读及幻读问题
读已提交(RC)
存在不可重复读及幻读问题
可重复读(RR)
仍存在幻读问题
可序列化(S)
# 锁机制
- 共享锁(S)
- 排他锁(X)
- 意向共享锁(IS)
- 意向排他锁(IX)
# InnoDB解决RR级别下的幻读问题
快照读(读取记录的可见版本,如普通查询请求:无锁,并发度高)
借助MVCC实现
若读取的数据正在执行删/改操作,读取操作将不会等待该行排它锁的释放,而是直接利用MVVC读取该行的数据快照
MVVC避免了对数据重复加锁的过程,大大提高了读操作的性能
当前读(读取记录的最新版本,如加共享锁(
in share mode)/排他锁(for update)的查询请求以及删/改请求)借助行锁(Next-Key Lock,即Record Lock + Gap Lock)实现
- 批量更新时(出现大量行锁),行锁可能升级为表锁
- 不根据索引进行查询时,行锁将升级为表锁
# 最佳实践
- 控制事务的大小,减少锁定的资源量和锁的持有时间,提高并发度:在不影响业务逻辑的前提下,尽量将可能持有行锁(可能进行当前读)的请求置于最后执行
(待验证)
# 原子性:借助事务机制实现
# 一致性:借助redo log + undo log实现
# 隔离性
# 持久性:借助redo log + undo log实现
# 索引执行成本计算
# IO成本
# CPU成本
# 高可用
# 主从配置(MySQL 5.7)
# Master
GRANT REPLICATION SLAVE ON *.* TO `repl`%`@` IDENTIFIED BY `repl`
FLUSH PRIVILEGES
SHOW MASTER STATUS;
记录File及Position变量值
# Slave(Docker)
# 启动
docker run --name mysql5.7_slave --restart always -p 13306:3306 -v /etc/mysql/slave/my.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf -v /var/lib/mysql/slave:/var/lib/mysql -e MYSQL_ROOT_PASSWORD="PASSWORD" -d mysql:5.7
# 配置
# RESET SLAVE;
# 填入Master端记录的File及Position变量值
CHANGE MASTER TO MASTER_HOST = 'MASTER_IP', MASTER_PORT = 3306, MASTER_USER = 'repl',
MASTER_PASSWORD = 'MASTER_PASSWORD', MASTER_LOG_FILE = 'master-bin.000001', MASTER_LOG_POS = 154;
START SLAVE;
SHOW SLAVE STATUS;
查看Slave_IO_State值是否为Waiting for master to send event,Slave_IO_Running与Slave_SQL_Running值是否均为Yes
如果有一个值不为
Yes,则可能是容器重启后的事务回滚引起的:STOP SLAVE; SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1; START SLAVE;
Redis基础 →